Publications
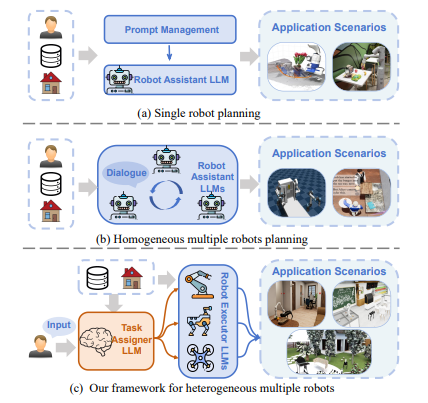
COHERENT: Collaboration of Heterogeneous Multi-Robot System with Large Language Models
[ arXiv ]
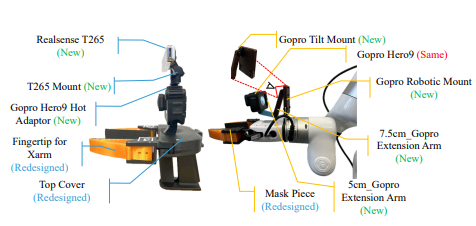
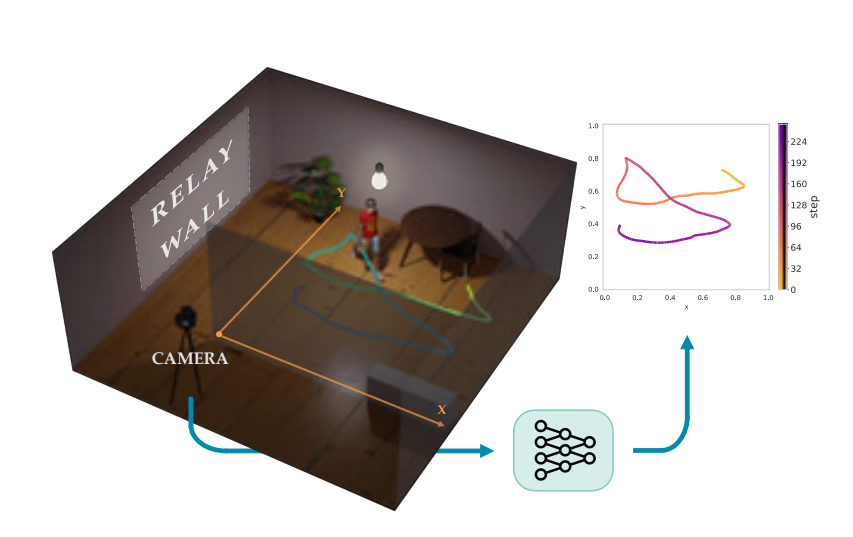
Fast-UMI: A Scalable and Hardware-Independent Universal Manipulation Interface
[ arXiv ]
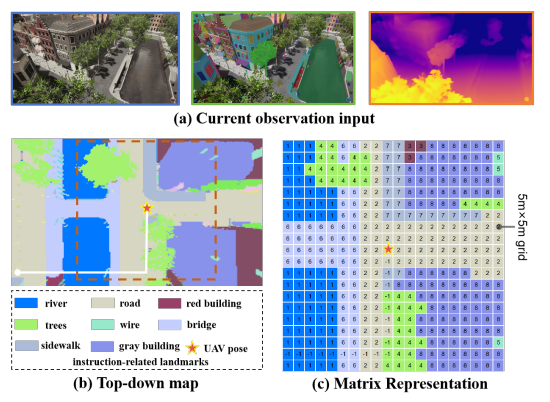
Aerial Vision-and-Language Navigation via Semantic-Topo-Metric Representation Guided LLM Reasoning
[ arXiv ]
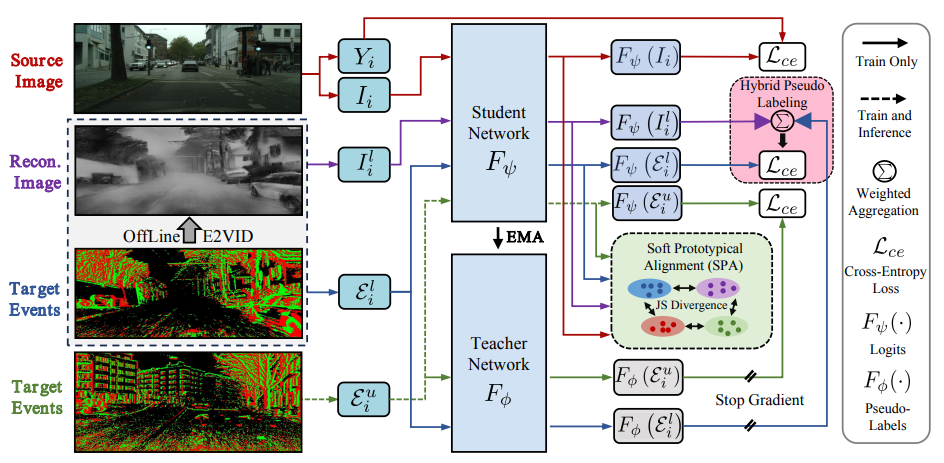
HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation
[ CVPR 2024 ]
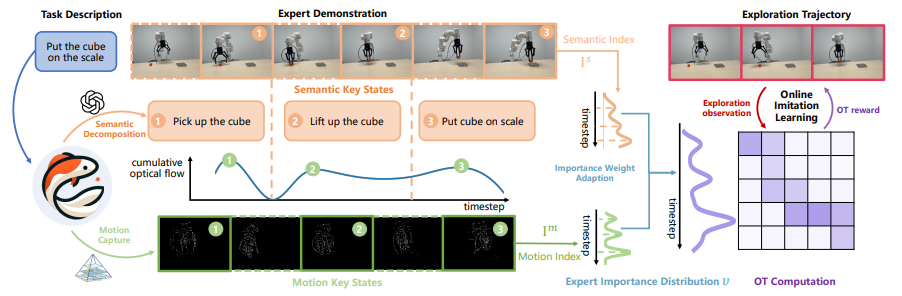
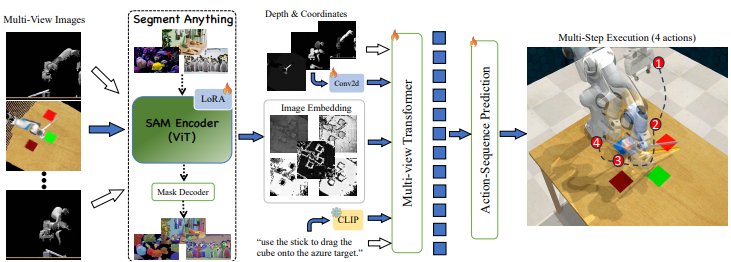
SAM-E: Leveraging Visual Foundation Model with Sequence Imitation for Embodied Manipulation
[ ICML 2024 ]
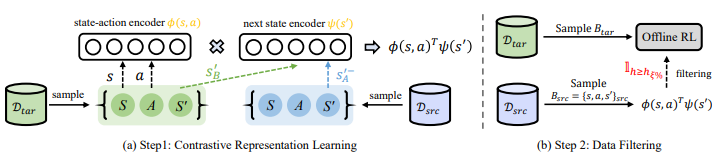
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
[ ICML 2024 ]
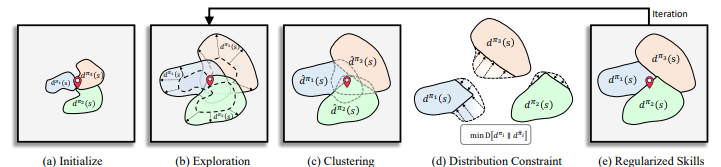
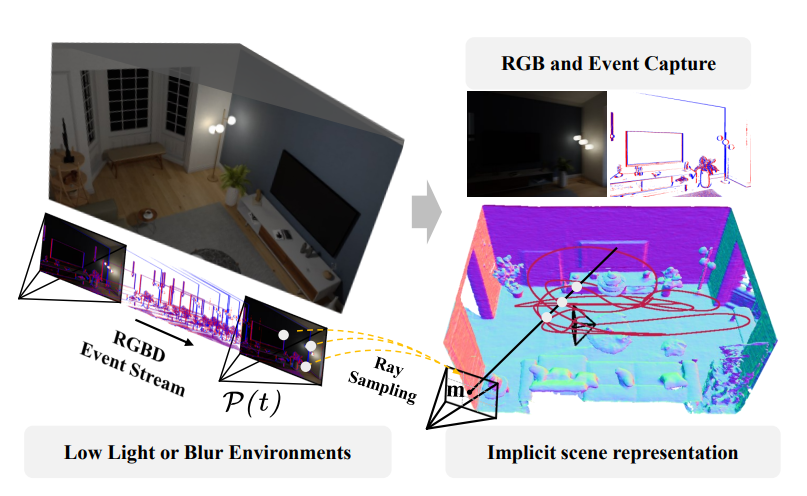
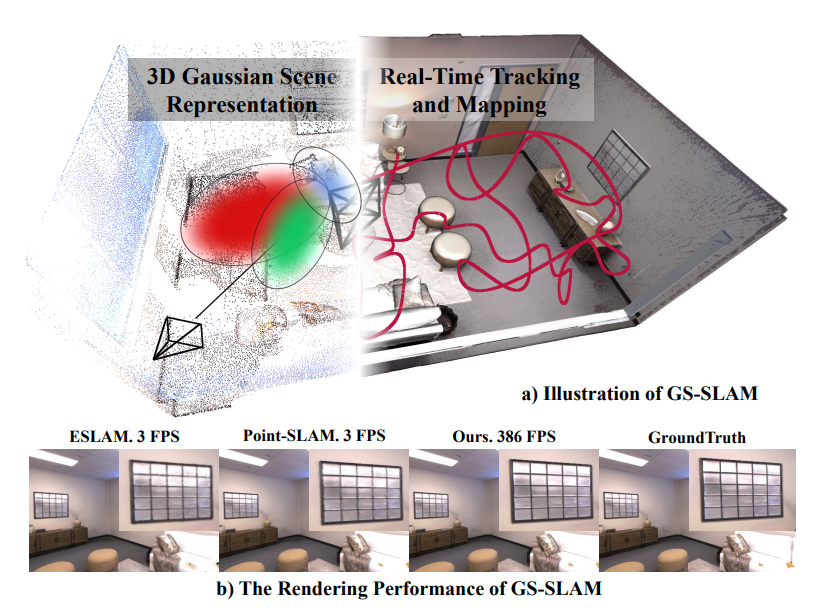
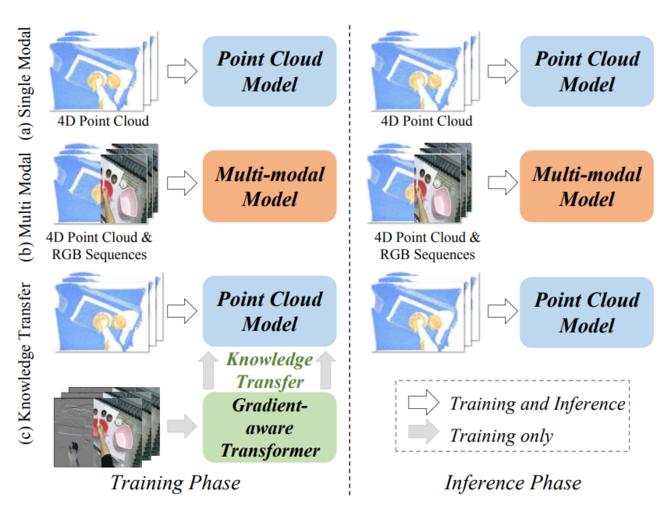
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
[ AAAI 2024 ]
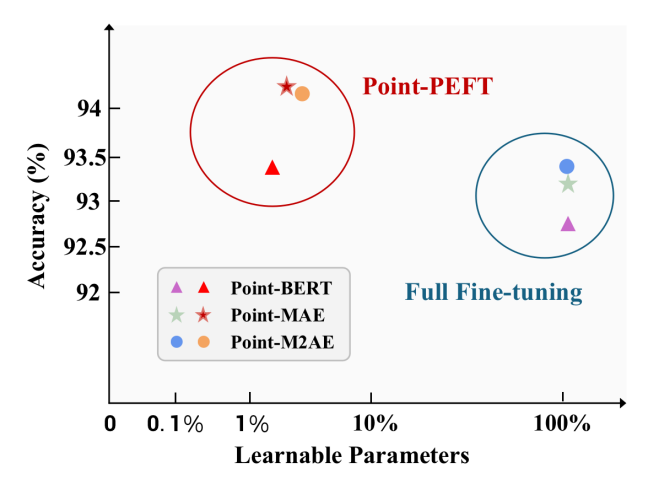
Point-PEFT: Parameter-Efficient Fine-Tuning for 3D Pre-trained Models
[ AAAI 2024 ]
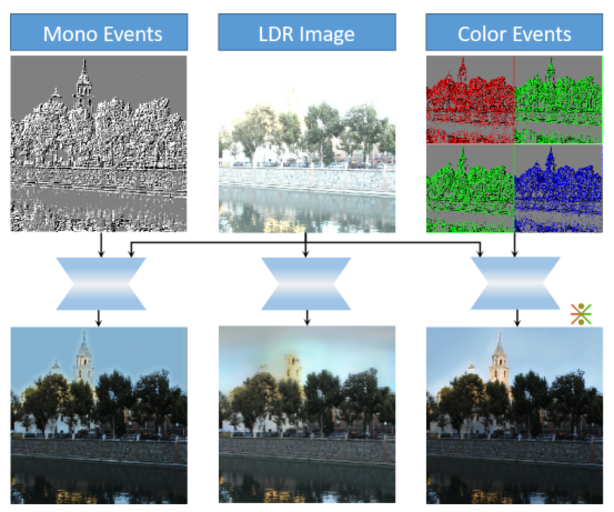
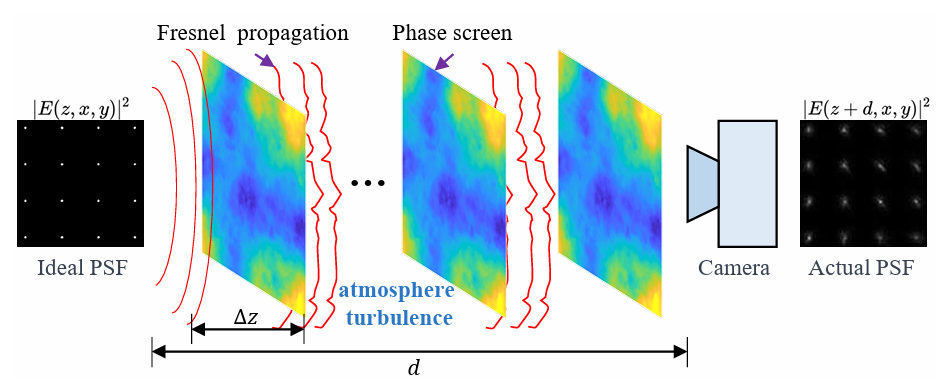
ASF-Transformer: neutralizing the impact of atmospheric turbulence on optical imaging through alternating learning in the spatial and frequency domains
[ Optics Express ]
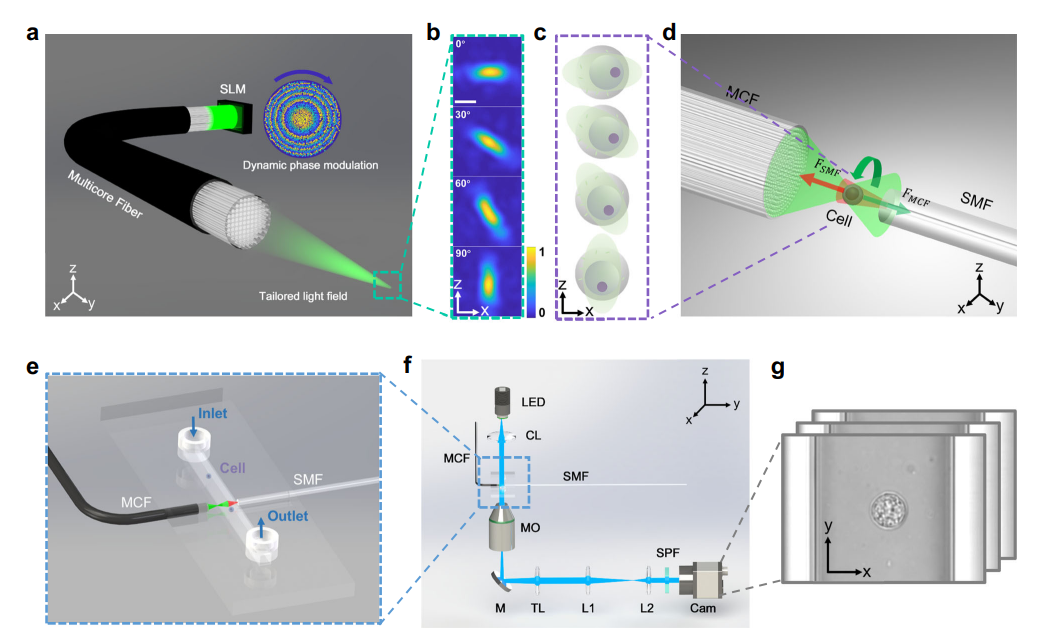
AI-driven projection tomography with multicore fibre-optic cell rotation
[ Nature Communications ]
研发世界首台基于光纤光学操控的显微层析成像原理样机;首次实现光纤光控癌细胞三维旋转,完成人类白血病细胞全三维重建,推动细胞级癌症早期诊疗与靶向药物开发。

Calibration-free quantitative phase imaging in multi-core fiber endoscopes using end-to-end deep learning
[ Optics Letters ]
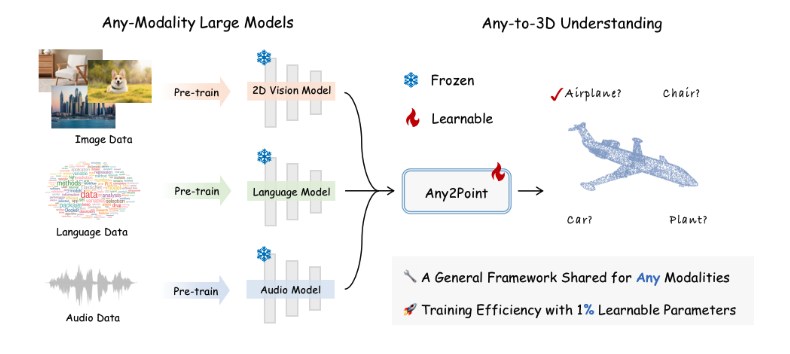
Any2Point: Empowering Any-modality Large Models for Efficient 3D Understanding
[ ECCV 2024 ]
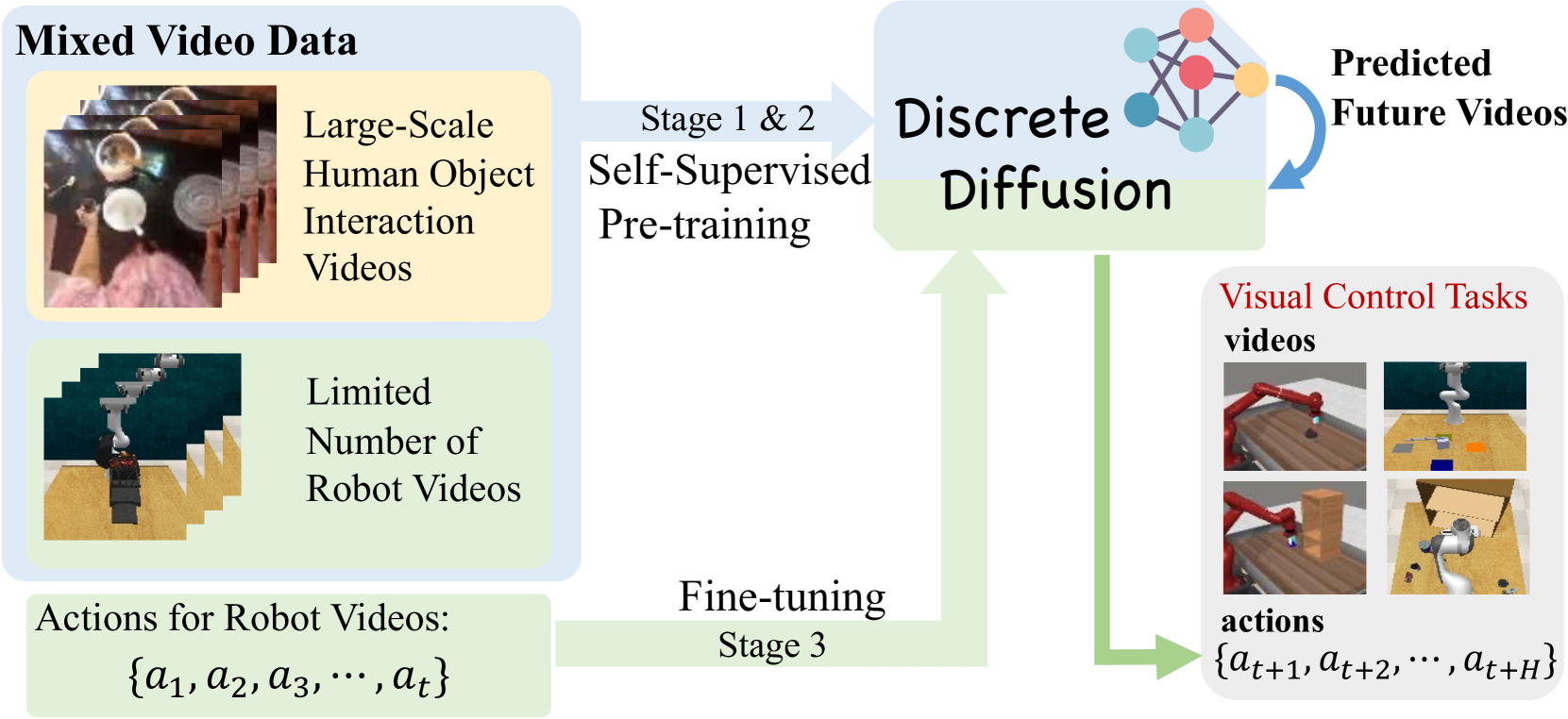
Large-Scale Actionless Video Pre-Training via Discrete Diffusion for Efficient Policy Learning
[ arXiv ]
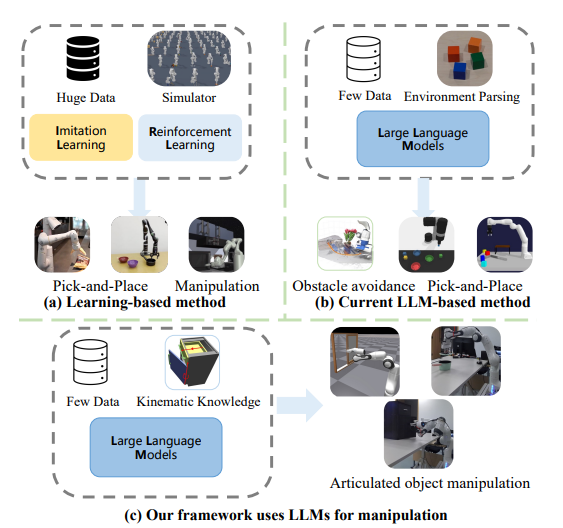
Kinematic-aware Prompting for Generalizable Articulated Object Manipulation with LLMs
[ ICRA 2024 ]

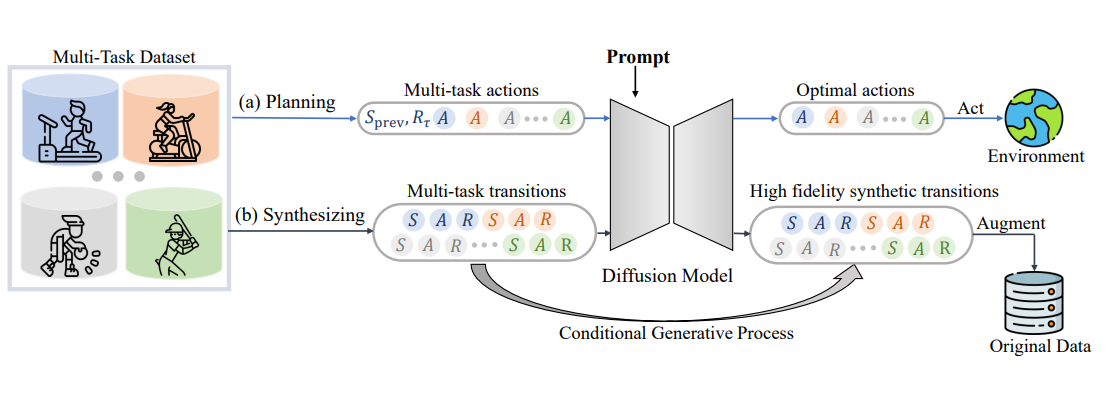
Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
[ NeurIPS 2023 ]
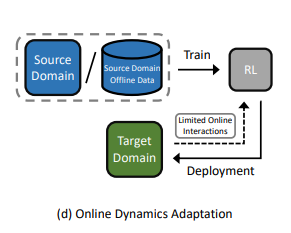
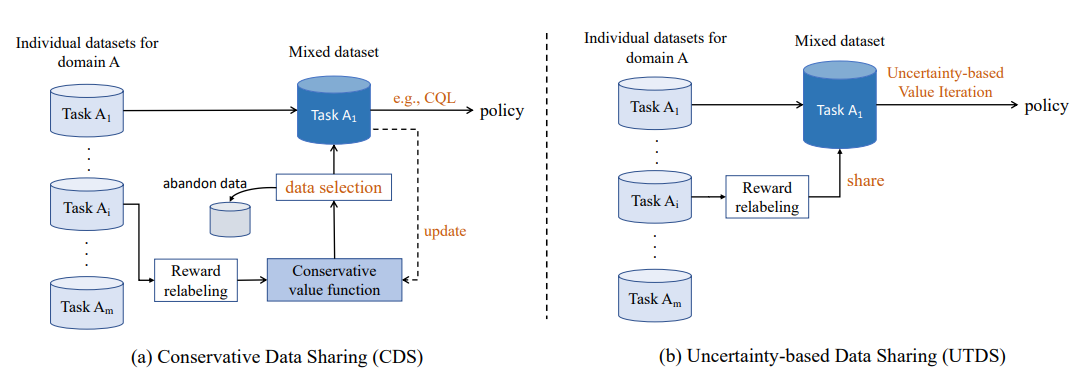
Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning
[ Artificial Intelligence ]

Vehicle Perception from Satellite
[ IEEE transactions on pattern analysis and machine intelligence ]
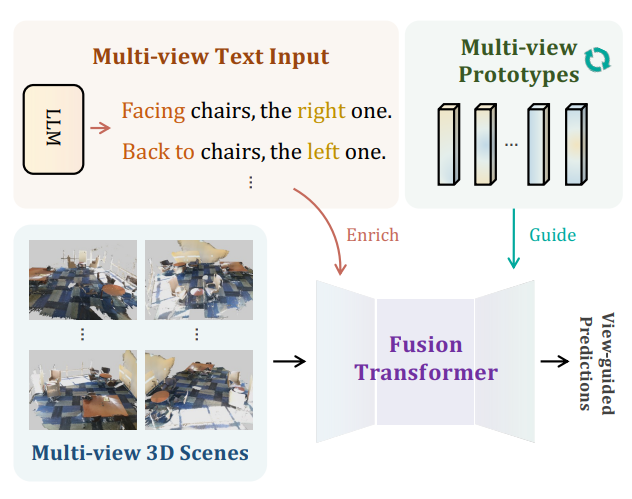
ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding with GPT and Prototype Guidance
[ ICCV 2023 ]
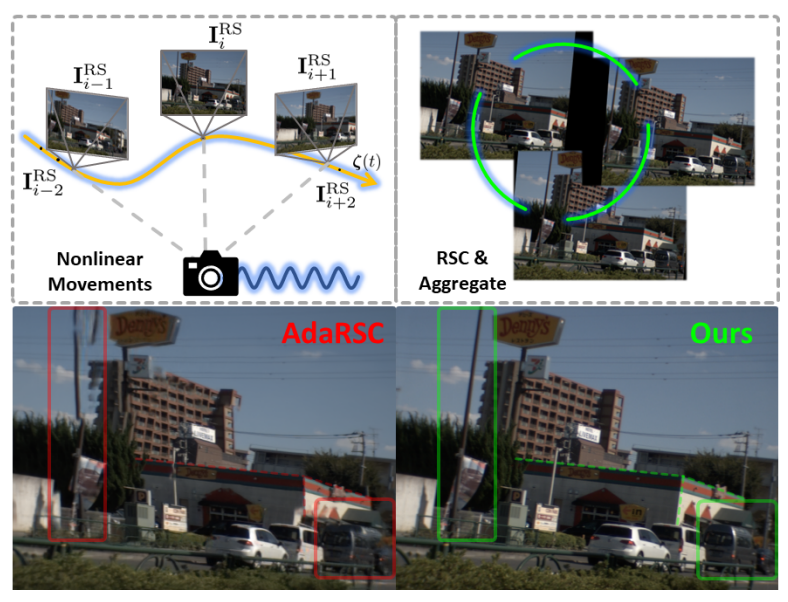
Towards Nonlinear-Motion-Aware and Occlusion-Robust Rolling Shutter Correction
[ ICCV 2023 ]
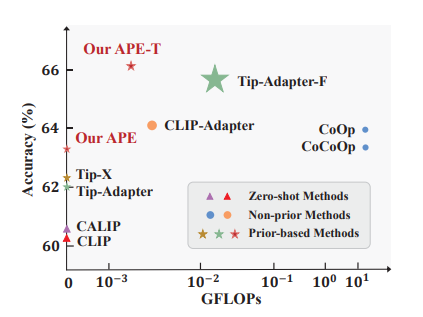
Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement
[ ICCV 2023 ]
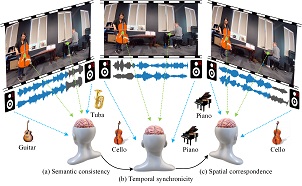
Bio-Inspired Audiovisual Multi-Representation Integration via Self-Supervised Learning
[ ACM MM 2023 ]
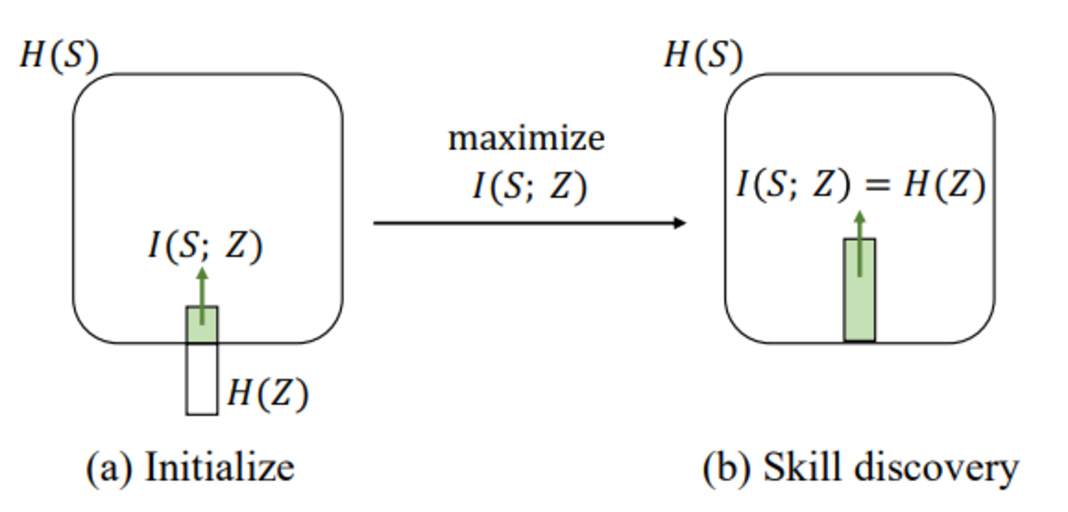
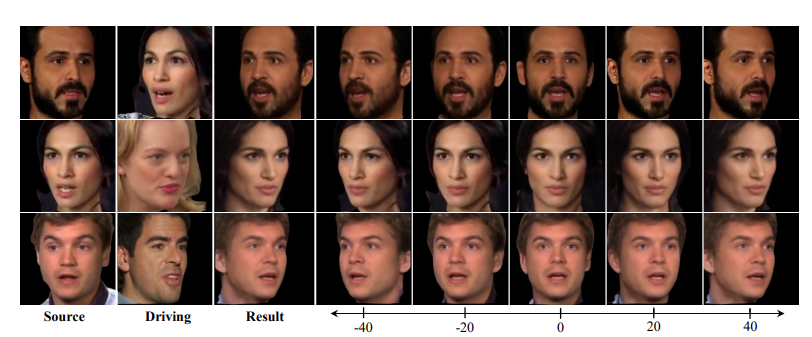
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
[ CVPR 2023 ]